6Náhodné vektory a súvis medzi náhodnými premennými
Odteraz budeme načas hovoriť o náhodnom vektore. Je to vektor náhodných premenných definovaných na rovnakom pravdepodobnostnom priestore. V tejto kapitole sme hovorili o dvojrozmernom náhodnom vektore, teraz to rozšírime a budeme hovoriť o \(n\)-rozmernom náhodnom vektore \((X_1,X_2,\dots,X_n)^T.\)
Tento pojem je kľúčový na pochopenie štatistického testovania hypotéz, o ktorom budeme hovoriť neskôr. Ide o triviálne rozšírenie dvojrozmerného náhodného vektora, ktorý sme opisovali skorej.
Ak sú časti náhodného vektora spojite rozdelené, popisujeme pravdepodobnostné správanie pomocou združenej funkcie hustoty\(f_{X_1,X_2,\dots,X_n}(x_1,x_2,\dots,x_n): \mathbb{R}^n \rightarrow \mathbb{R}^{+},\) ktorá spĺňa nasledovnú vlastnosť
Hovoríme, že náhodné premenné \(X_1,X_2,\dots,X_n\) sú združene nezávislé, ak platí:
\[\forall x_1 \in \mathcal{S}_{X_1}, \dots, \forall x_n \in \mathcal{S}_{X_n}: p_{X_1,X_2,\dots,X_n}(x_1,x_2,\dots,x_n) = p_{X_1}(x_1) \dots p_{X_n}(x_n),\] ak sú diskrétne rozdelené a
\[\forall x_1 \in \mathbb{R}, \dots, \forall x_n \in \mathbb{R}: f_{X_1,X_2,\dots,X_n}(x_1,x_2,\dots,x_n) = f_{X_1}(x_1) \dots f_{X_n}(x_n).\] ak sú spojite rozdelené.
Nezávislé náhodné premenné spolu vôbec nesúvisia. Preto informácia o správaní jednotlivých náhodných premenných je postačujúca na úplný popis celého pravdepodobnostného vektora.
Príklad 6.1 Majme dve náhodné premenné \((X, Y)\), ktorých pravdepodobnostná funkcia je popísaná nasledovnou tabuľkou:
Neplatí. Takže sme našli protipríklad na nezávislosť, takže náhodné premenné \(X\) a \(Y\) nie sú nezávislé. Nemusíme už skúšať ďalšie kombinácie. Napriek tomu, že sú nezávislé, tak majú koreláciu rovnú nule.
To len hovorí o tom, že korelácia je špecifická miera závislosti, konkrétne lineárnej závislosti.
6.1 Závislosť náhodných premenných
Teraz vieme, čo znamená keď sú náhodné premenné nezávislé. Keď sú dve, ale odteraz aj keď ich je viacej. Ak náhodné premenné nie sú nezávislé, mohli by sme chcieť merať ako veľmi sú závislé.
Je veľa rôznych mier závislosti dvojíc náhodných premenných. Jednou z nich je korelácia, teda miera lineárnej závislosti.
Pripomeňme si ju:
Kovarianciou dvoch náhodných premenných \(X_1, X_2\) nazývame
\(-1 \leq \text{Corr}[X_1,X_2] \leq 1\), je bezrozmerná, t.j. nemá žiadne jednotky,
\(\text{Corr}[X_1,X_2] = \text{Corr}[X_2,X_1]\) takže korelácia je symetrická,
\(\text{Corr}[X_1,X_2] = \pm 1 \implies \exists a,b \in \mathbf{R}: X_1 = aX_2+b\), nadobúda hodnoty \(\pm 1\) práve vtedy, keď je jedná náhodná premenná lineárnou funkciou druhej,
\(X_1\) a \(X_2\) sú nezávislé \(\implies \text{E}[X_1 X_2] = \text{E}[X_1]\text{E}[X_2] \implies \text{Corr}[X_1,X_2]=0\)
Ilustratívny príklad s dinosaurom, kedy korelácia nedobre popisuje mieru závislosti, lebo závislosť nie je lineárna je tu.
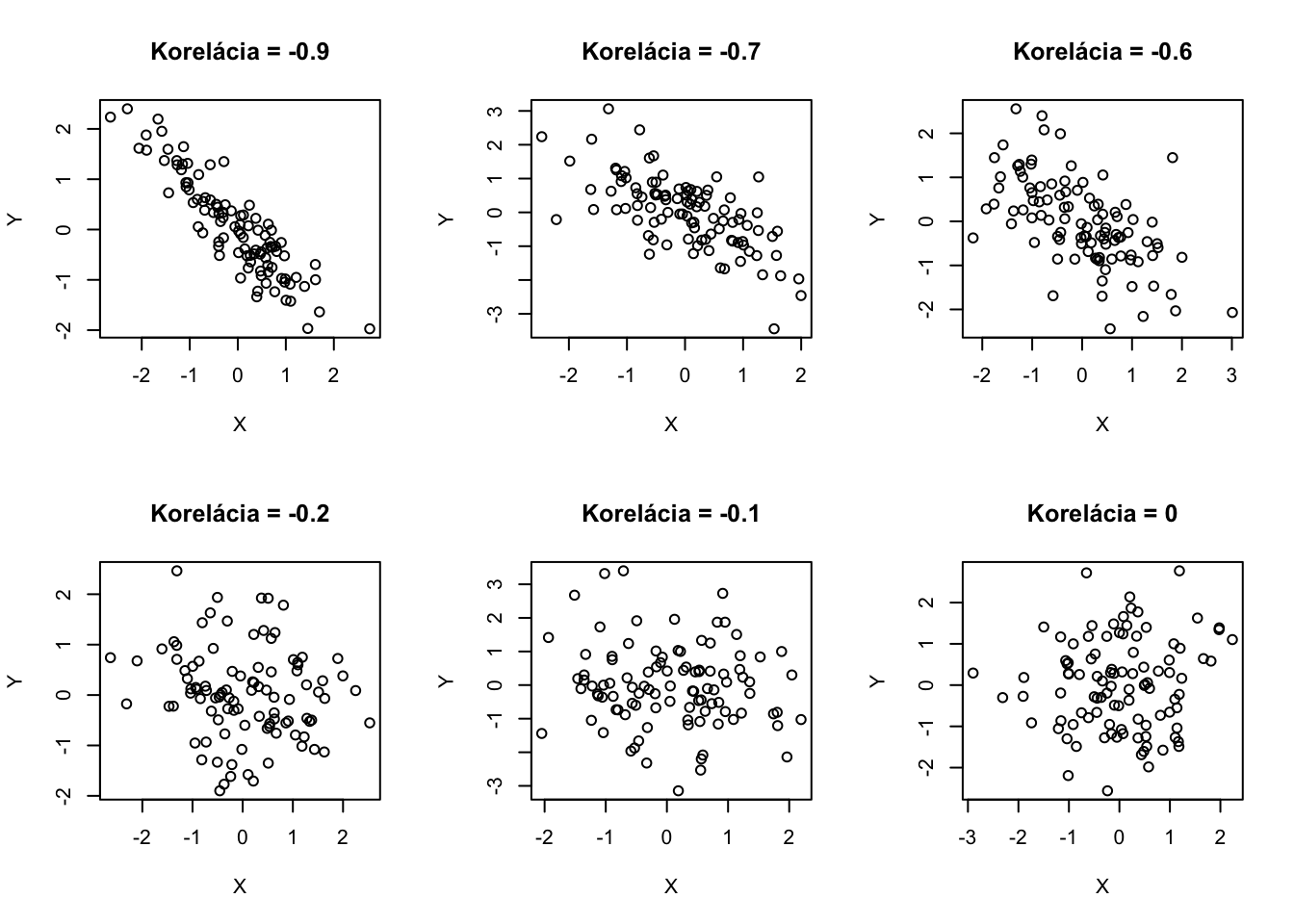
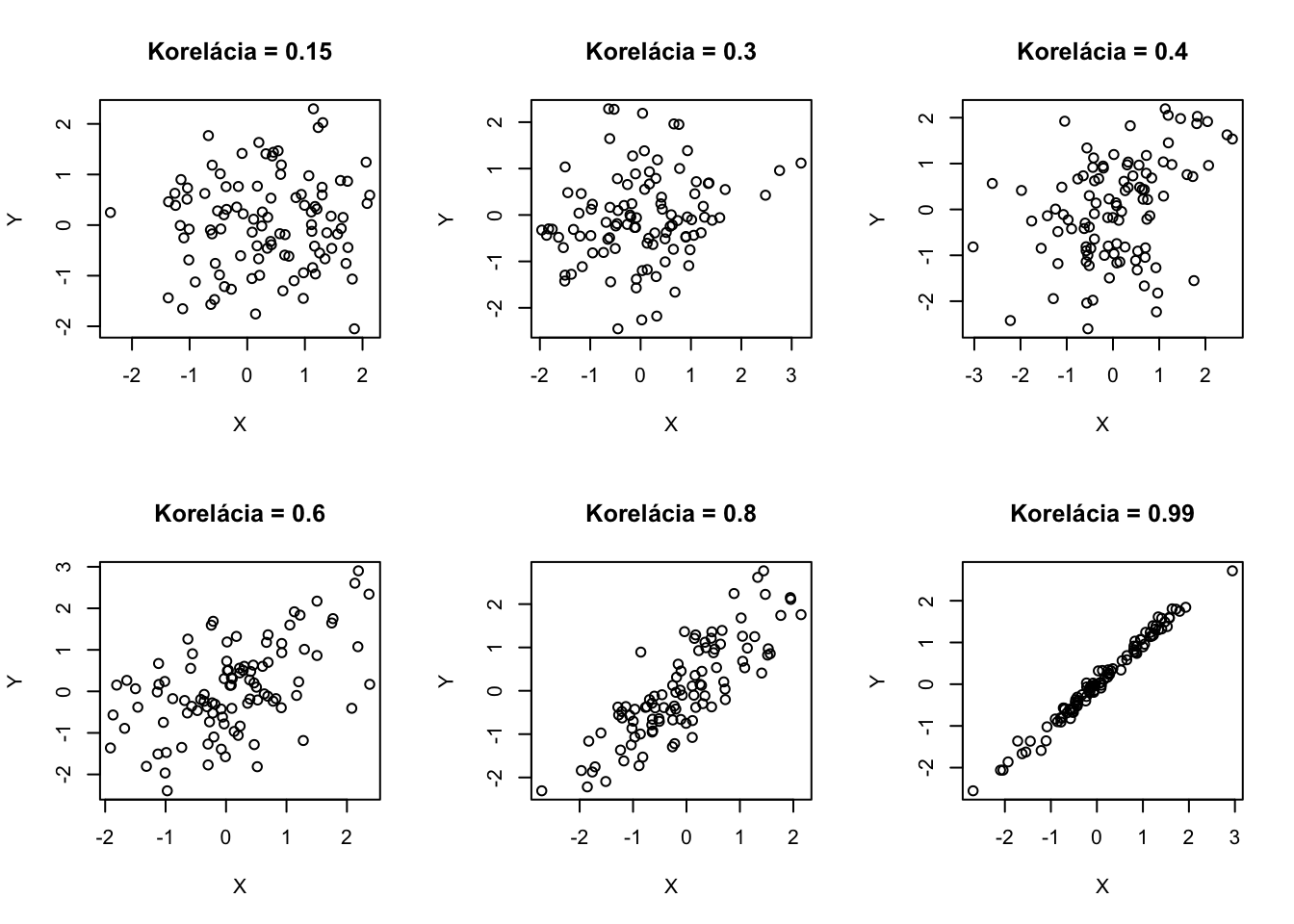
Tu je Rkový kód, ktorý generuje dvojice dát s rôznymi závislosťami Takto vyzerá realizácia 100 náhodných vektorov \((X,Y)\) s rôznymi koreláciami.
par(mfrow=c(2,3))library(mvtnorm)set.seed(12922)rho <-c(-0.9,-0.7,-0.6,-0.2,-0.1, 0, 0.15,0.3,0.4, 0.6,0.8,0.99)for (iRho in1:length(rho)){ x <-rmvnorm(100,sigma=matrix(c(1,rho[iRho],rho[iRho],1),nrow=2))plot(x[,1],x[,2],main=paste("Korelácia =",rho[iRho]),xlab="X",ylab="Y")}
Korelačná štruktúra náhodného vektora \(X\) je popísaná korelačnou maticou\(\text{Corr}[X]\), ktorej \(i,j\)-ty prvok je daný \(\text{Corr}[X_i,X_j]\):
je symetrická (lebo \(\text{Cov}[X_i,X_j]=\text{Cov}[X_j,X_j]\)) a okrem toho
je kladne semidefinitná, takže \[a^T\text{Var}[X]a \geq 0,\] pre akýkoľvek vektor \(a \in \mathbb{R}^n.\) Toto platí lebo \(\text{Var}[a^T X] = a^T\text{Var}[X]a\) a zároveň vieme, že \(\text{Var}[Z] \geq 0\) pre akúkoľvek náhodnú premennú a teda aj pre \(Z=a^T X.\)
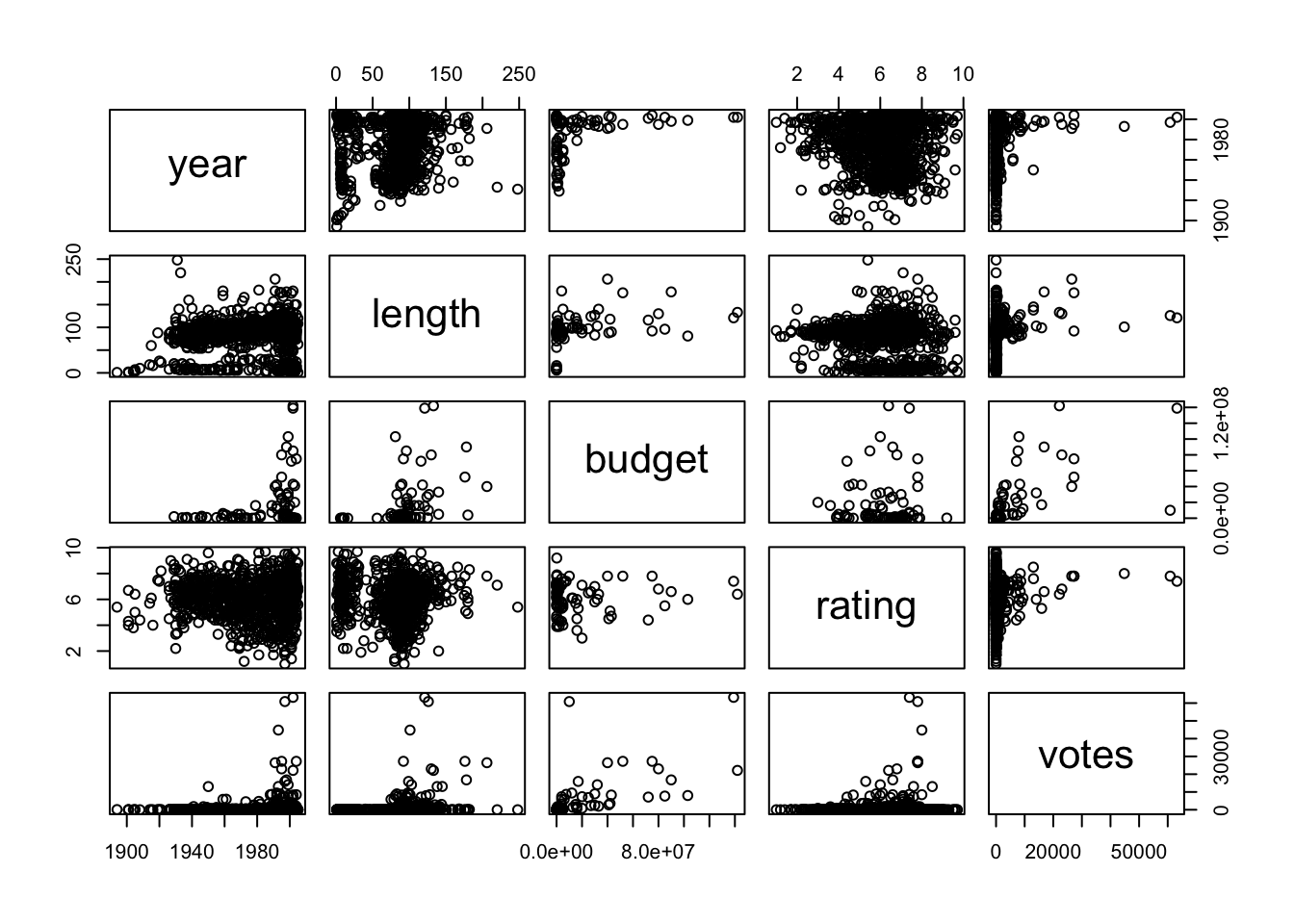
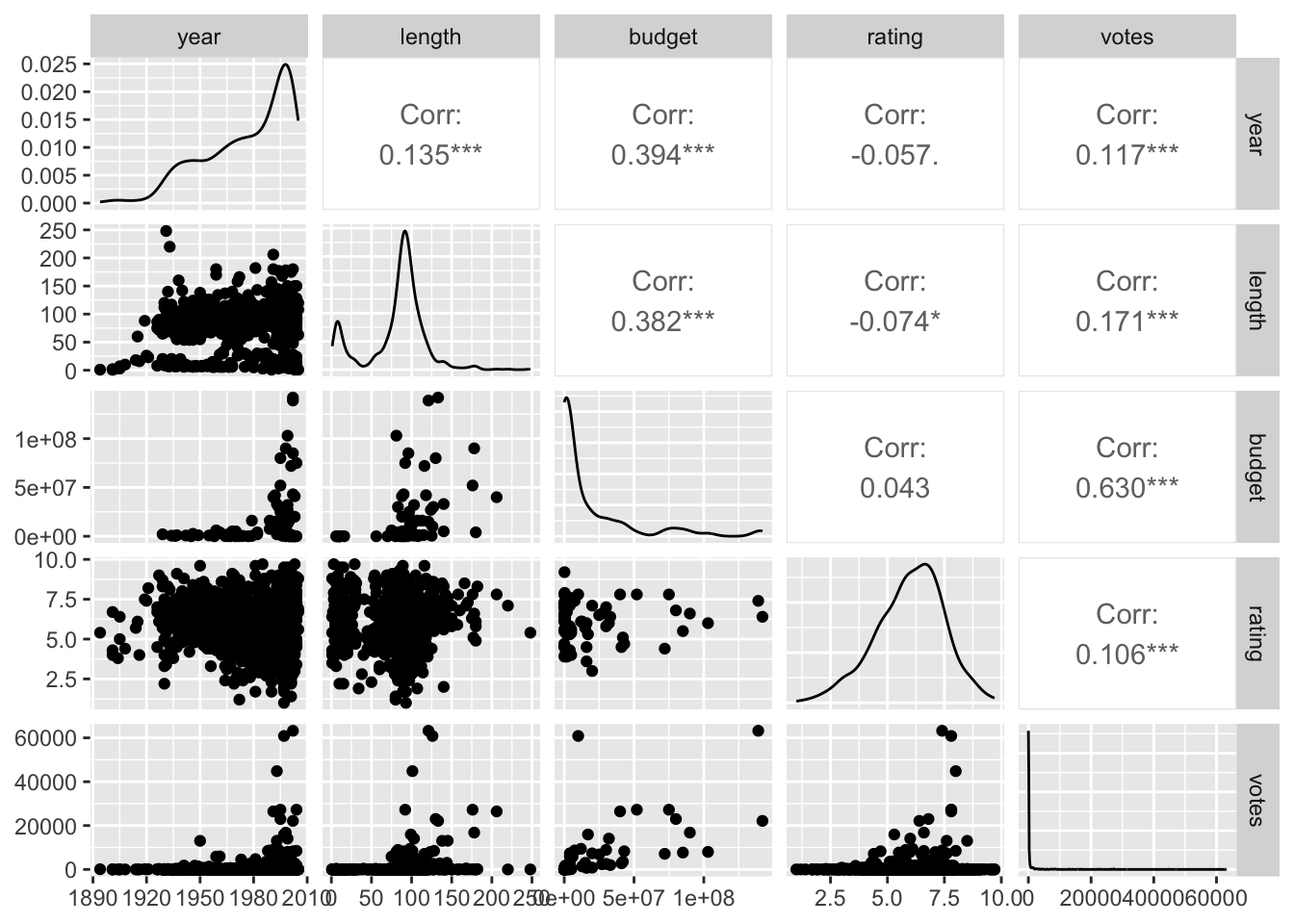
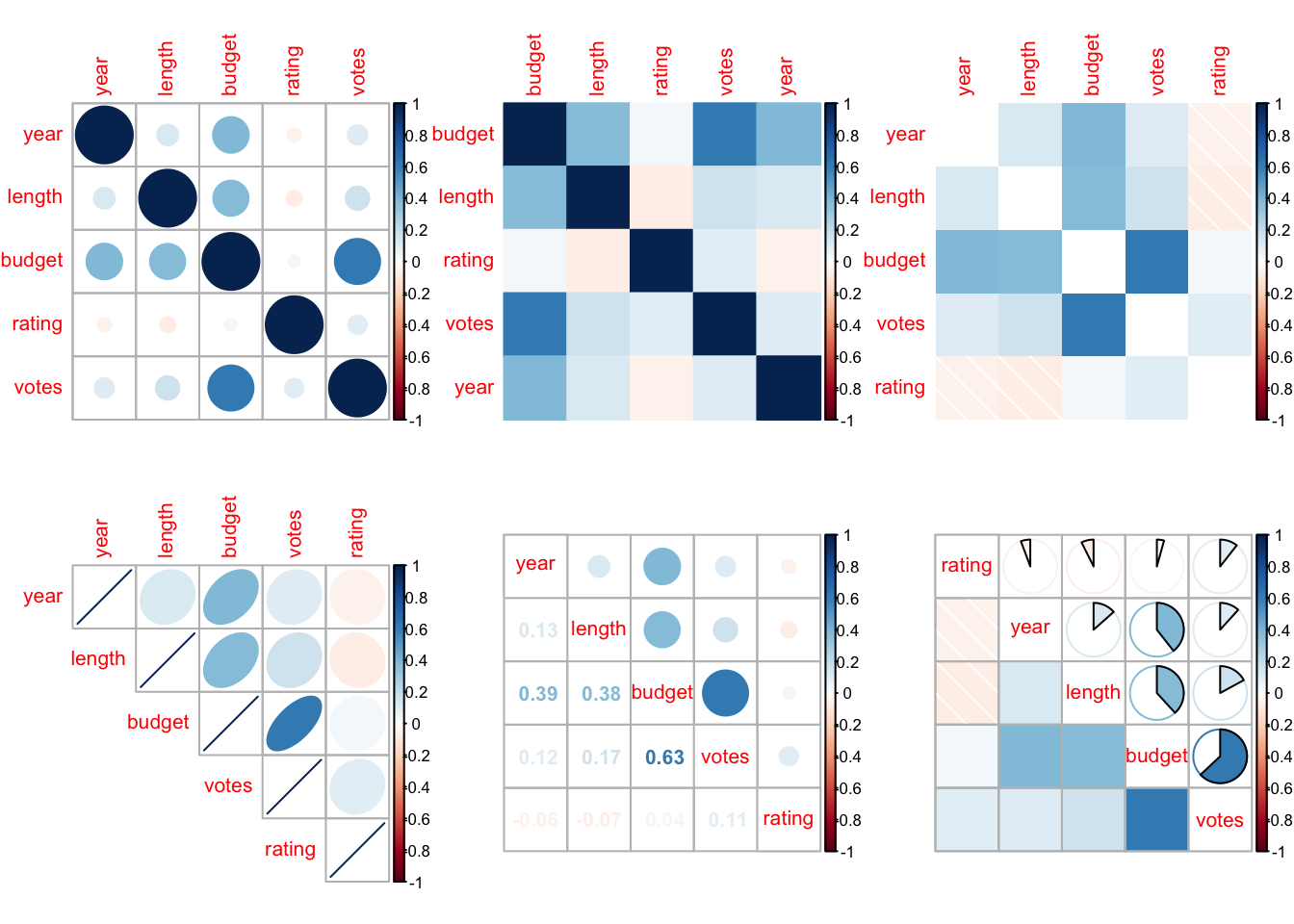
Príklad 6.2 Pozrime sa na korelácie rôznych premenných náhodnej podvzorky filmov z knižnice ggplot2movies.
Alebo krajší párový graf s využitím knižnice GGally.
options(warn =-1)library(GGally)
Loading required package: ggplot2
Registered S3 method overwritten by 'GGally':
method from
+.gg ggplot2
ggpairs(data_sam)
Korelačné matice sa dajú rôzne zobraziť, aby odkomunikovali súvzťažnosť jednotlivých premenných. Tu sú nejaké príklady:
par(mfrow=c(2,3))library(corrplot)
corrplot 0.95 loaded
cor_matrix <-cor(data_sam,use="pairwise.complete.obs")corrplot(cor_matrix)corrplot(cor_matrix, method ='color', order ='alphabet')corrplot(cor_matrix, method ='shade', order ='AOE', diag =FALSE)corrplot(cor_matrix, method ='ellipse', order ='AOE', type ='upper')corrplot.mixed(cor_matrix, order ='AOE')corrplot.mixed(cor_matrix, lower ='shade', upper ='pie', order ='hclust')
Príklad 6.3 Tu je situácia, keď je jedna premenná priamo lineárnou transformáciou druhej. Konkrétne \(X_3 = 2-3X_2\)
Teraz vidíme, že \(\text{Corr}[X_2,X_3]\) je “skoro” \(-1\).
6.2 Korelácia nie je kauzalita
Toto ste počuli už mnohokrát.
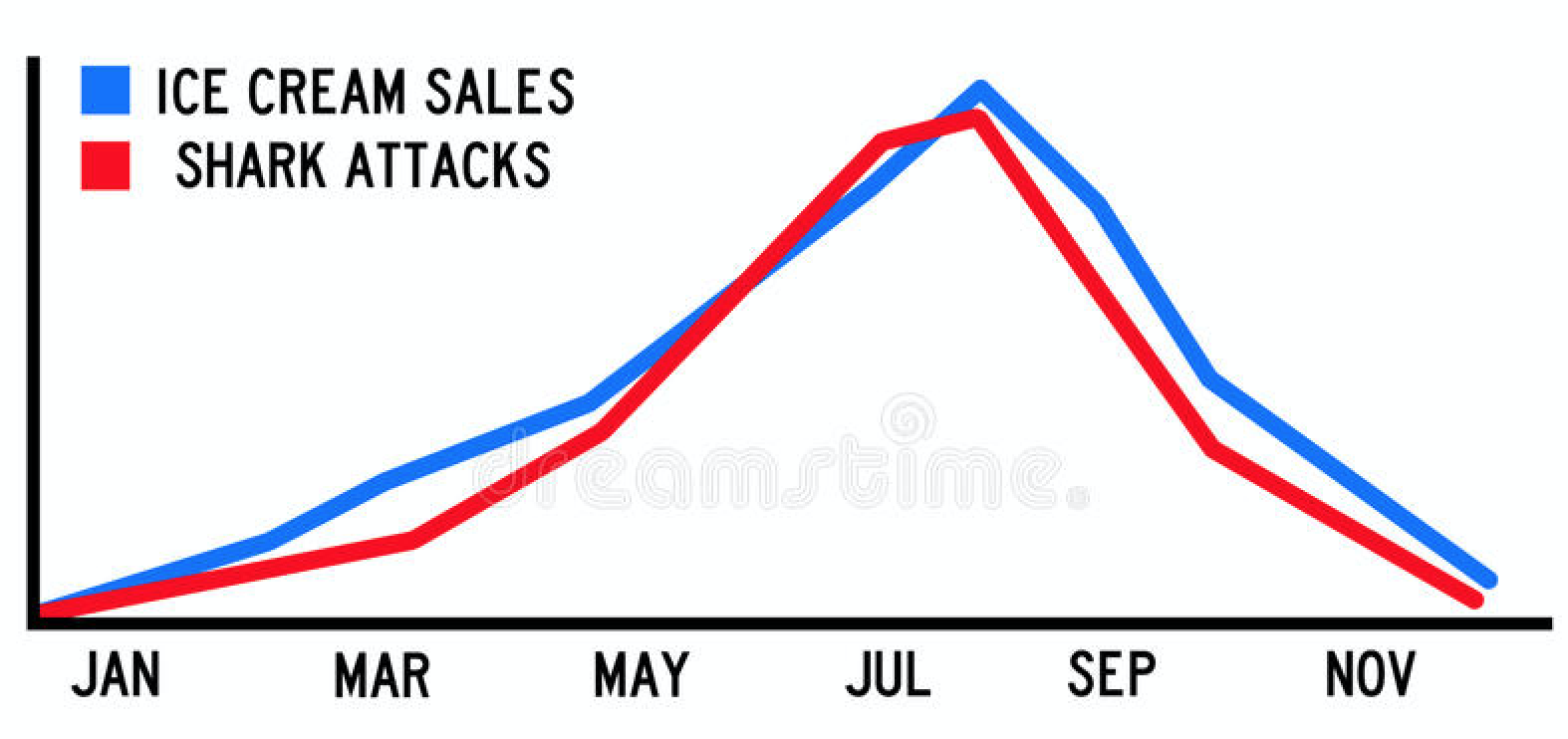
Doteraz sme nič nehovorili o tom, že čo je príčina, čo je následok, ako veci spolu kauzálne súvisia. A robili sme tak náročky. Pozrite sa na nasledujúci obrázok:
Korelácia nie je to isté ako kauzalita. (zdroj: www.dreamstime.com)
Útoky žralokov sú veľmi silno korelované s objemom predanej zmrzliny. Ale neznamená to to, že jedno spôsobuje druhé. V tomto prípade majú obe premenné zjavne silnú časovú zložku. V lete je teplo, ľudia sa viacej kúpu a vtedy aj žraloky majú na koho útočiť. Na druhej strane v zime sa nám príliš nežiada studenej zmrzliny.
Na idenfikovanie príčiny a dôsledku, na odlíšenie asociácie od kauzality potrebujeme nejaký zdroj náhody. Ako v prípade randomizovanej štúdie v medicíne. Náhodne rozdelíme pacientov/tky na tých, ktorí dostanú liek a tých ktorí dostanú placebo. Ak sú tieto vzorky naozaj podobné (a ak máme pacientov/tky dostatočne veľa, tak budú podobné), tak je to naozaj ten liek a nie niečo iné čo mení prognózu pacienta/tky.
Vo všeobecnosti je ťažké odlíšiť koreláciu od kauzality. Pozorované dáta, ktoré sú neexperimentálne, nás len málokedy informujú priamo o kauzálnom efekte. Zamyslite sa nad tým keď budete nabudúce pri rannej káve čítať noviny o tom, koľko káv denne Vám predĺži/skráti život.
Príklad 6.4 Toto je obrovská otázka, ktorej sa venuje veľká časť ekonómie pracovného trhu (labor economics). V dátach vidíme, že vzdelaní ľudia zarábajú v priemere viacej. Znamená to, že absolovovanie vysokej školy zvýši Vašu mzdu?
Príklad 6.5 Mať malé triedy je drahé. Plat učiteľa/ľky je tým najvýznamnejším nákladom pri vzdelávaní. Oplatí sa mať triedy kde bude menej žiakov/čok?
Príklad 6.6 Niekedy nie sú experimentálne dáta dostupné z etických alebo iných príčin (nemôžem jednu skupinu náhodne vybraných ľudí prinútiť fajčiť, inej to zasa zakázať). Napriek tomu máme množstvo mechanizmov, ktorých pochopenie nám umožňuje porozumieť mechanizmu príčiny a následku napriek neexistencii experimentálnych dát. Dokonca Sir Ronald Fisher, jeden z najvýznamnejších štatistikov upozorňoval, že na základe korelácie nemožno odvodiť kauzálne závery. Dnes už je absolútny vedecký konsenzus o škodlivosti fajčenia. Napriek neexistencii experimentu. Mimochodom, Fisher bol tuhý fajčiar.
Zamyslite sa, prečo je náročné odpovedať na tieto otázky:
Ovplyvňuje vzdelanie rodičov vzdelanie deti?
Predlžujú tri malé kávy denne život o 7%?
Je Keto diéta lepšia ako vysokosacharidová, čo sa týka vytrvalostných športov?
Zvyšuje globalizácia životnú úroveň?
Pomáha chrániť vitamín C pred nachladnutím?
Spôsobí zvýšenie dane z príjmu štátne príjmy alebo narastie objem čiernej práce?
Je skríningové vyšetrenie vzácneho typu rakoviny vhodné?
Vedie polarizácia spoločnosti k nárastu preferencií politických strán ďalej od stredu?
Zvyšuje nedostatok spánku šancu Alzheimerovej choroby?
To, že je to náročné však neznamená, že to nie je možné. V mnohých situáciách experiment nie je možný a preto svoje porozumenie problému skladáme z veľkého množstva malých dielčích indícií.
Cvičenie 6.2 Pomocou simulácie overte vzťah \(\text{Var}[a^T X] = a^T\text{Var}[X]a\) pre nejakú voľbu trojrozmerného náhodného vektora \(X\), ktorý vygenerujte s viacrozmerného normálneho rozdelenia pomocou funkcie rmvnorm z knižnice mvtnorm. Vyskúšajte rôzne trojrozmerné vektory \(a\).
Cvičenie 6.3 Nech \(X_3 = 3X_1 + X_2,\) kde \(X_1 \sim N(20,3^2)\) a \(X_2 \sim N(30,6^2)\) a zároveň \(X_1\) a \(X_2\) sú nezávislé.
Aká je variancia \(X_3\)?
Aká je kovariancia \(X_2\) a \(X_3\)?
Aká je korelácia \(X_2\) a \(X_3\)?
Porovnajte teoretické hodnoty s tými, ktoré ste odhadli pomocou simulácií.
Preskúmajte variabilitu Vašich odhadov. Aká počet simulácií je dostatočný na uspokojivú odpoveď (teoretické hodnoty sú dostatočne blízke tým, ktoré sú odhadnuté pomocou simulácií.)?
Cvičenie 6.4 Vhodne zobrazte korelačnú maticu premenných: koncentrácie ozónu, úrovne slnečného žiarenia, rýchlosti vetra a teploty z datasetu airquality z knižnice datasets.
Cvičenie 6.5 Dataset EuStockMarkets z knižnice datasets obsahuje denné dáta cien Európskych burzových indexov počas 90-tych rokov. Zobrazte ich do prehľadného grafu. Naviac zobrazte korelačnú štruktúru denných výnosov (výnos v dni \(t\) je definovaný ako \(\frac{p_{t}-p_{t-1}}{p_{t-1}},\) kde \(p_t\) je cena cenného papiera na konci dňa \(t\).).
Cvičenie 6.6 Dataset USArrests z knižnice datasets má informácie o zatknutiach na 100’000 obyvateľov pre rôzne Americké štáty v roku 1973. Zobrazte korelačnú štruktúru týchto dát, pozrite sa ako sú asociované rôzne typy zatknutí s percentom ľudí žijúcich v mestách.
Cvičenie 6.7 V datasete mtcars z knižnice datasets sú informácie o 32 autách z roku 1974. Pozrite sa korelačnú štruktúru týchto premenných.
:::
6.4 Domáca úloha 2
Prosím odovzdať do 2.11.2025 19:59 cez formulár (tento Vám príde emailom).
V riešeniach používajte prosím plnovýznamové vety a nahrávajte riešenia v jednom pdf súbore nazvanom podľa Vašich priezvísk v tvare DU1_priezvisko1_priezvisko2.pdf (napríklad DU1_Kovacova_Zelinka.pdf).