Nuž, nevieme, lebo \(X\) je náhodná. Je to síce pravdivá ale neuspokojivá odpoveď. Chceli by sme vedieť s akou pravdepodobnosťou nastane alebo nenastane. Už zloženie toho slova naznačuje, že má ambíciu merať to ako veľmi je táto udalosť “podobná pravde”. Existuje základné rozdelenie náhodných premenných podľa toho, či je množina hodnôt, ktoré môžu nadobúdať diskrétna alebo spojitá.
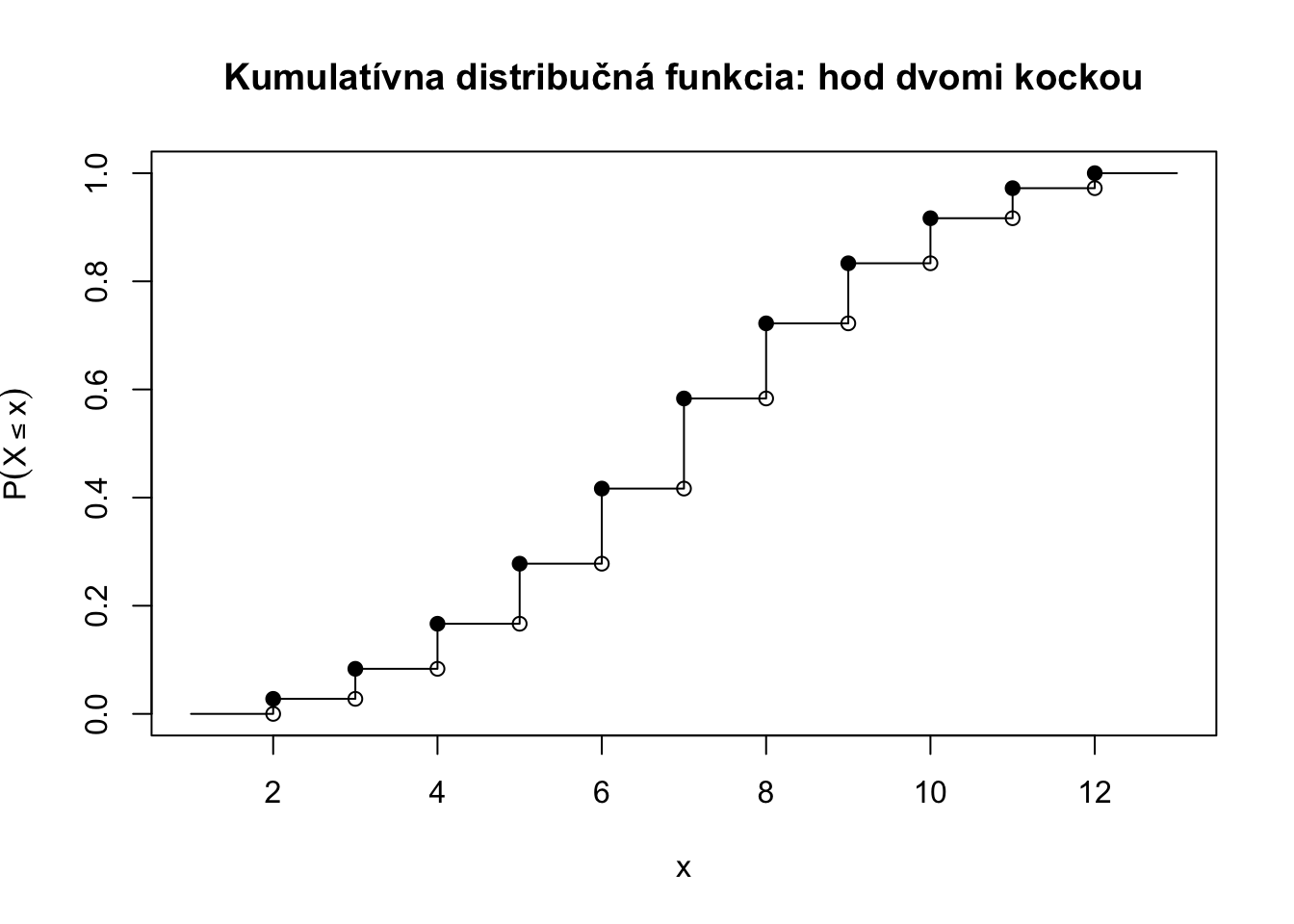
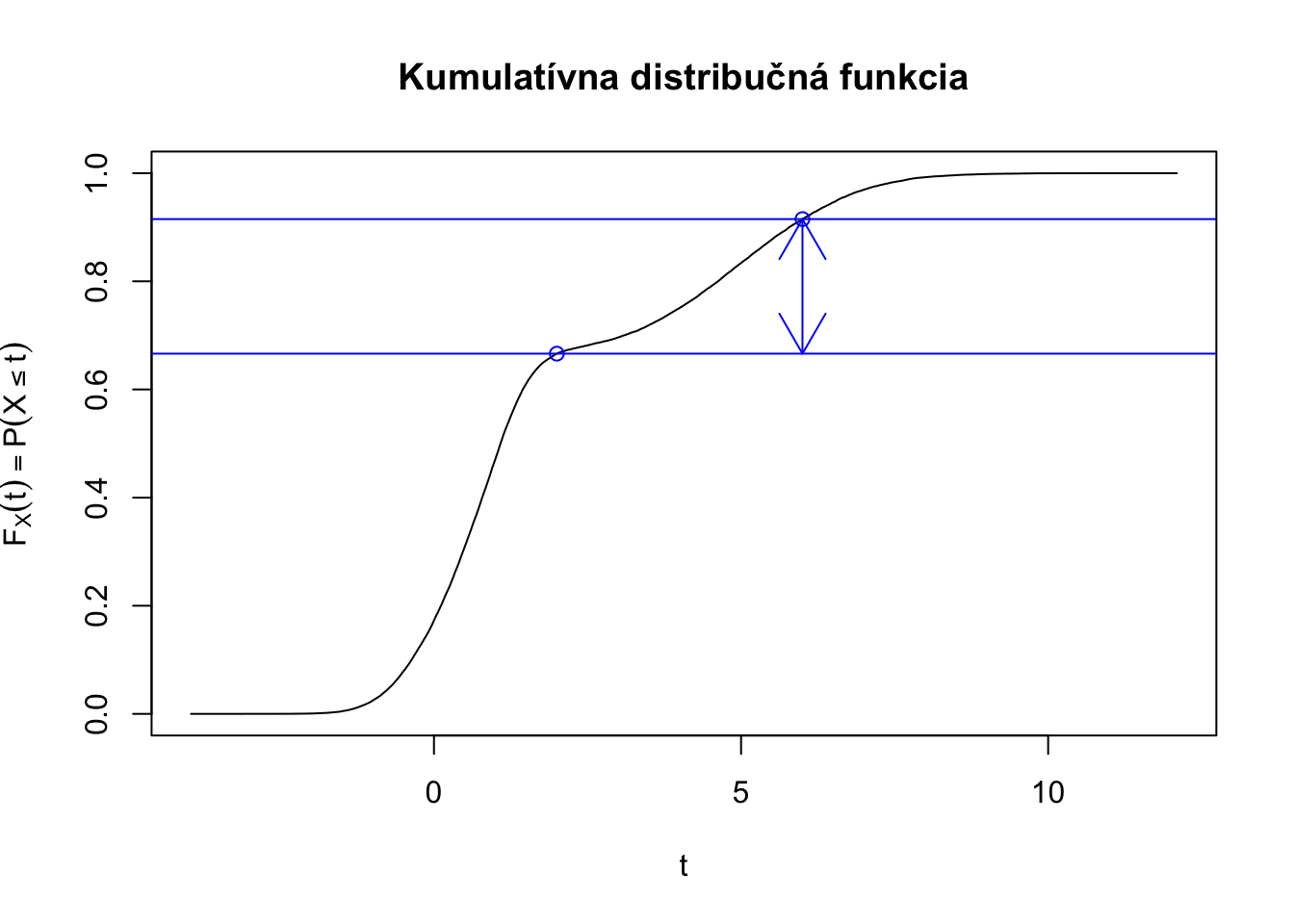
Náhodnú (diskrétnu aj spojitú) premennú môžeme charakterizovať kumulatívnou distribučnou funkciou. Distribučná funkcia náhodnej premennej \(X\) je funkcia \(F_X: \mathbb{R} \rightarrow \mathbb{R},\) ktorá je definovaná nasledovne:
\[F_X(x) = P(X \leq x).\]
5.1 Diskrétne náhodné premenné
Náhodná premenná je diskrétna ak nadobúda nanajvýš spočitateľne veľa hodnôt.
5.1.1 Pravdepodobnostná funkcia
Funkciu \(p_X: \mathcal{S}_X \rightarrow [0,1]\) definovanú nasledovne
Spojitá náhodná premenná nadobúda hodnoty na množine, ktorá je spojitá, teda môže nadobúdať nespočítateľne veľa hodnôt.
5.2.1 Funkcia hustoty
Na popis náhodnosti môžeme stále používať kumulatívnu distribučnú funkciu ale namiesto pravdepodobnostnej funkcie budeme používať funkciu hustoty (alternatívne funkciu hustoty spojite rozdelenej náhodnej premennej.)
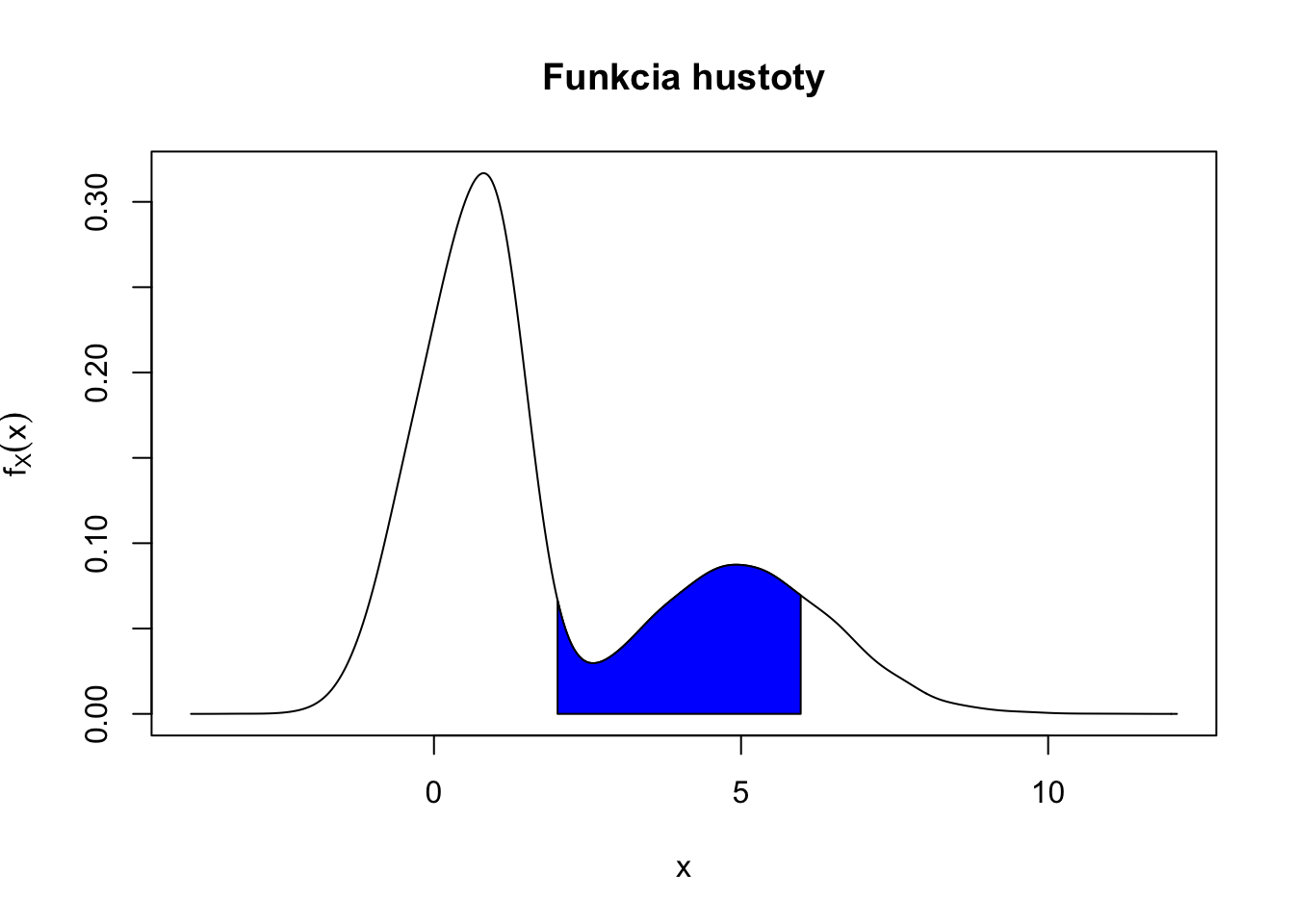
Hovoríme, že spojite rozdelená náhodná premenná \(X\) má funkciu hustoty \(f_X(x),\) kde \(f_X: \mathbb{R} \rightarrow \mathbb{R},\) ak platí:
\[P(a \leq X \leq b) = P(X \in [a,b]) = \int_{a}^b f_X(x) dx\]
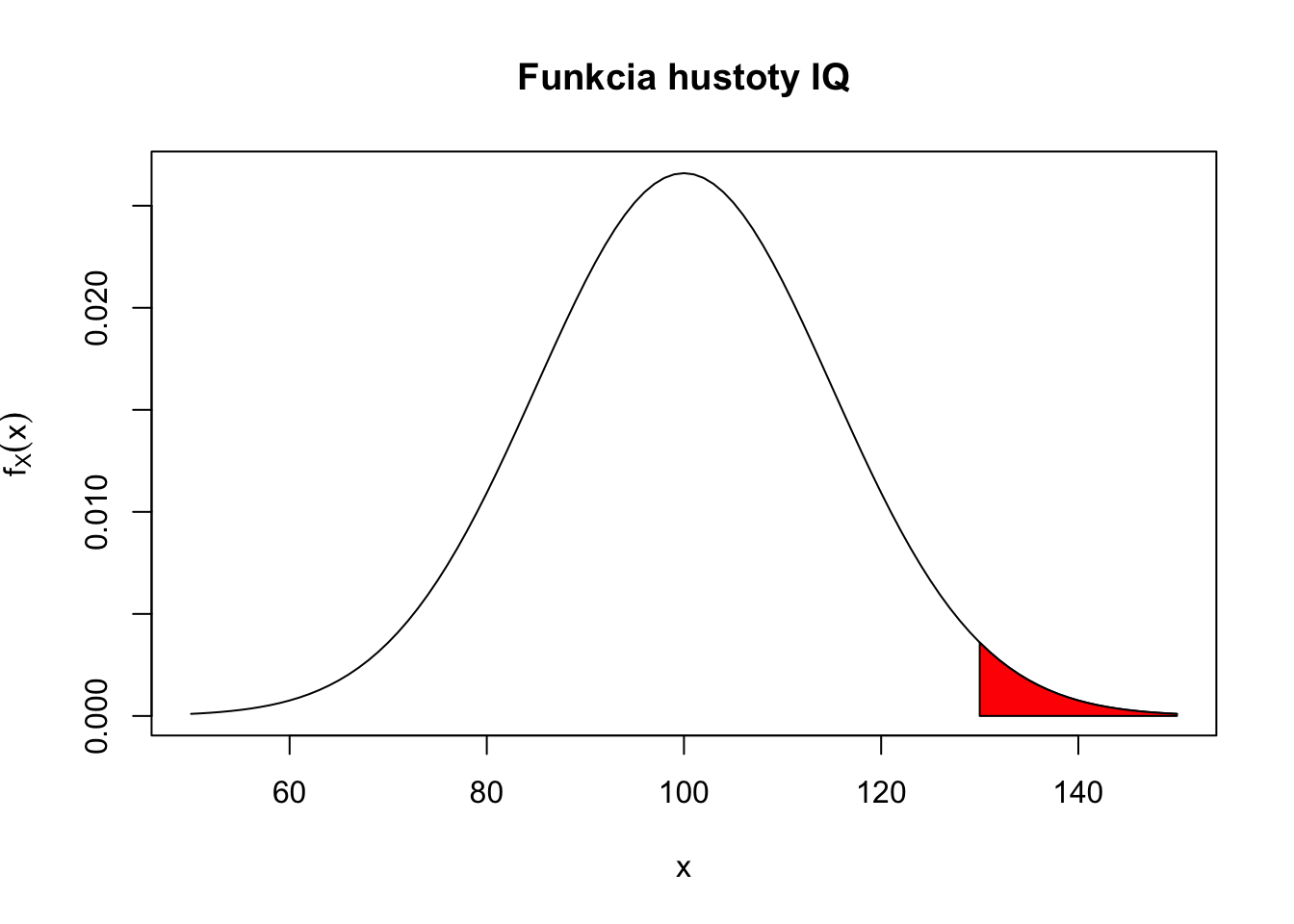
Príklad 5.3 Uvažujme náhodnú premennú \(X\), ktorá modeluje IQ náhodne vybraného človeka z danej populácie. Táto náhodná premenná má nasledovnú funkciu hustoty \(f_X(x) = \frac{1}{15\sqrt{2 \pi}} e^{-\frac{1}{2}\frac{(x-100)^2}{15^2}}\). Vypočítajte pravdepodobnosť, že náhodne vybraný človek z tejto populácie bude mať IQ väčšie ako 130.
Tento integrál nemá analytické (“pekné”) riešenie a treba ho zrátať numericky pomocou počítačového programu.
Nasledujúci obrázok túto situáciu ilustruje
x <-seq(50,150,by=1)y <-dnorm(x,100,15)plot(x, y, type="l",xlab =expression(x),ylab =expression(f[X](x)),main ="Funkcia hustoty IQ")value1 <-130value2 <-1000# Lower and higher indices on the X-axisl <-min(which(x >= value1))h <-max(which(x < value2))polygon(c(x[c(l, l:h, h)]),c(0, y[l:h], 0),col ="red")
\[\text{E}[X] = \int_{-\infty}^{\infty} x f_X(x) dx,\] ak \(\int_{-\infty}^{\infty} |x| f_X(x) dx < \infty.\) Teda ide o hodnoty \(x\) váhované hustotou pravdepodobnosti \(f_X(x).\)
\[\text{Var}[X] = \text{E}[(X-\text{E}[X])^2] = \int_{-\infty}^{\infty} (x - \text{E}[X])^2 f_X(x) dx,\] ak \(\int_{-\infty}^{\infty} |x^2| f_X(x) dx < \infty.\) Aj pre spojite rozdelenú náhodnú premennú platí \(\text{Var}[X] = \text{E}[X^2] - (\text{E}[X])^2.\)
Smerodajná odchýlka náhodnej premennej je (podobne ako pri diskrétnej náhodnej premennej) odmocnina z jej variancie
\[\text{sd}[X] = \sqrt{\text{Var}[X]}.\]
Príklad 5.4 Majme náhodnú premennú \(X\), ktorá má nasledovnú funkciu hustoty \(f_X(x) = \frac{1}{2}e^{-x/2}\) pre \(x > 0\) inak \(f_X(x)=0\). Vypočítajte \(\text{Var}[X].\)
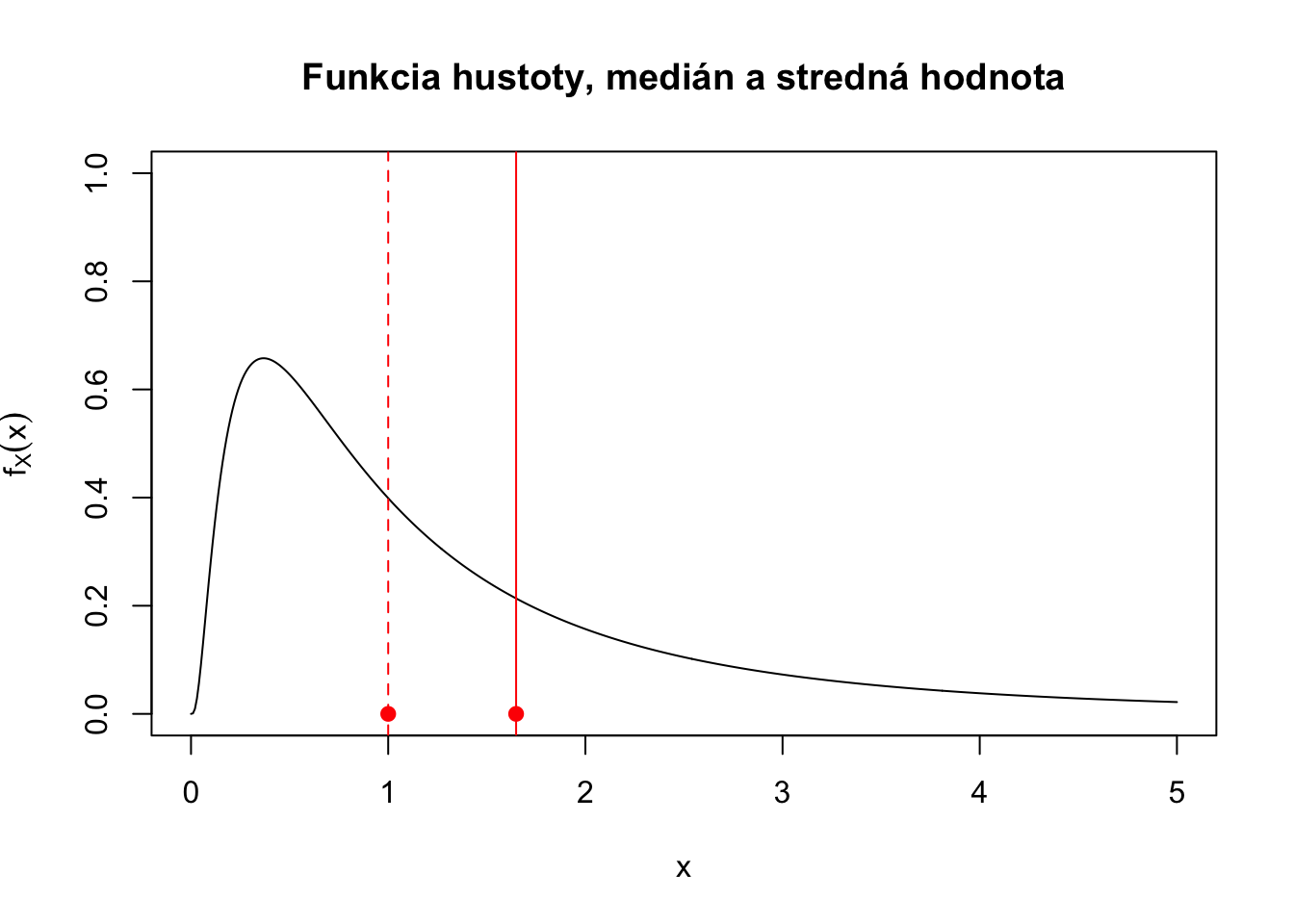
Medián spojite rozdelenej náhodnej premennej \(X\), je taká hodnota \(M\), pre ktorú platí
\[P(X \leq M)= P(X \geq M) = 0.5.\]
Medián je taká hodnota, že napravo aj naľavo od nej je 50% pravdepodobnostnej masy.
Nižšie sú dáta vygenerované z tzv. lognormálneho rozdelenia (náhodná premenná \(X\) má lognormálne rozdelenie ak \(\log(X)\) má normálne rozdelenie). Takéto rozdelenie je typické pre mzdy.
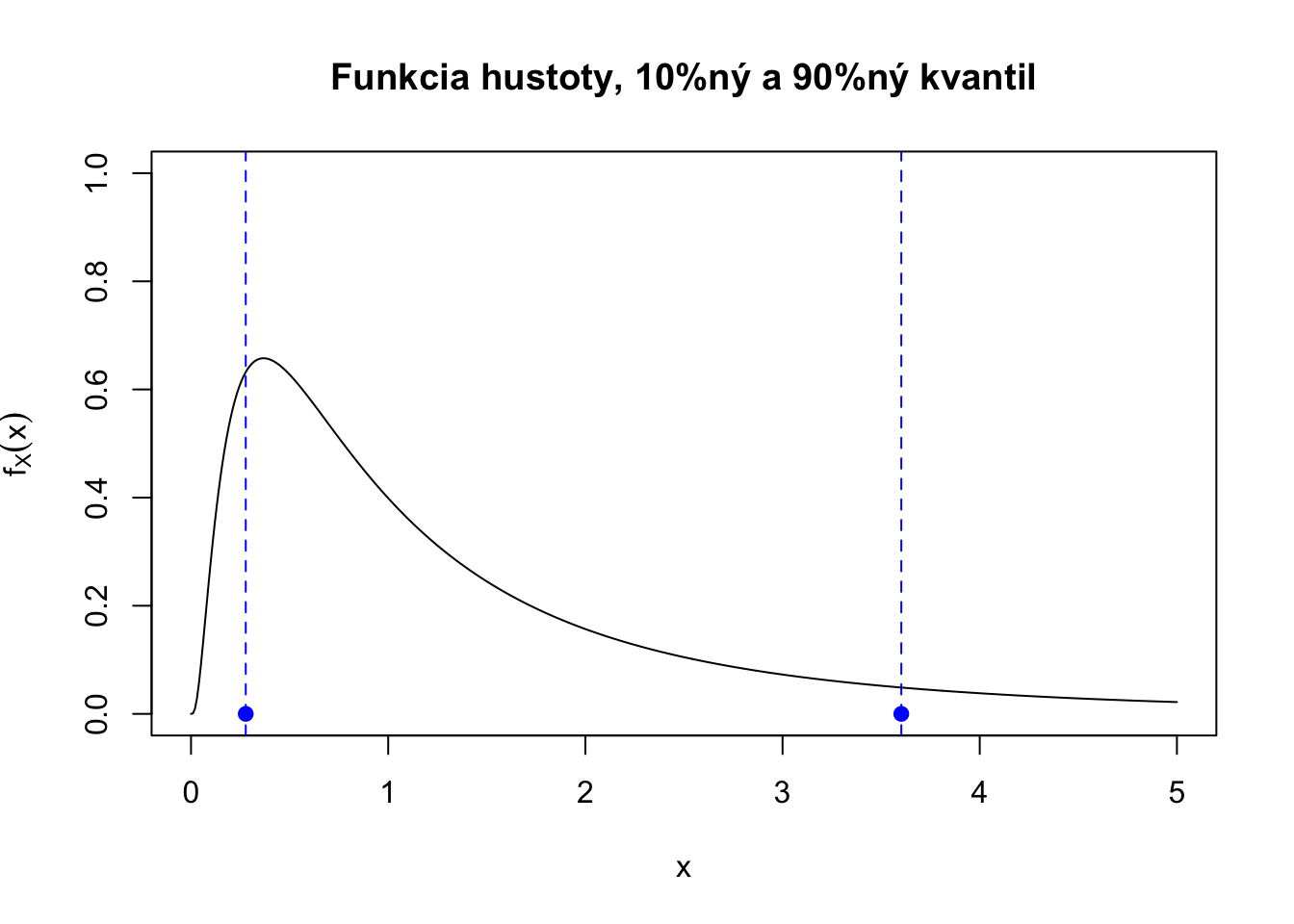
Medián je “hodnota v strede”. Na charakterizovanie pravdepodobnostnej distribúcie je častokrát zaujímavé pozrieť sa aj na kraje. Aspoň koľko zarába 5% najlepšie zarábajúcich? Aká je maximálna mzda 10% najhoršie zarábajúcich? Na toto odpovedá kvantil pravdepodobnostného rozdelenia.
\(p\)-percentný kvantil pravdepodobnostného rozdelenia náhodnej premennej \(X\) je taká hodnota \(Q_X(p)\), pre ktorú platí
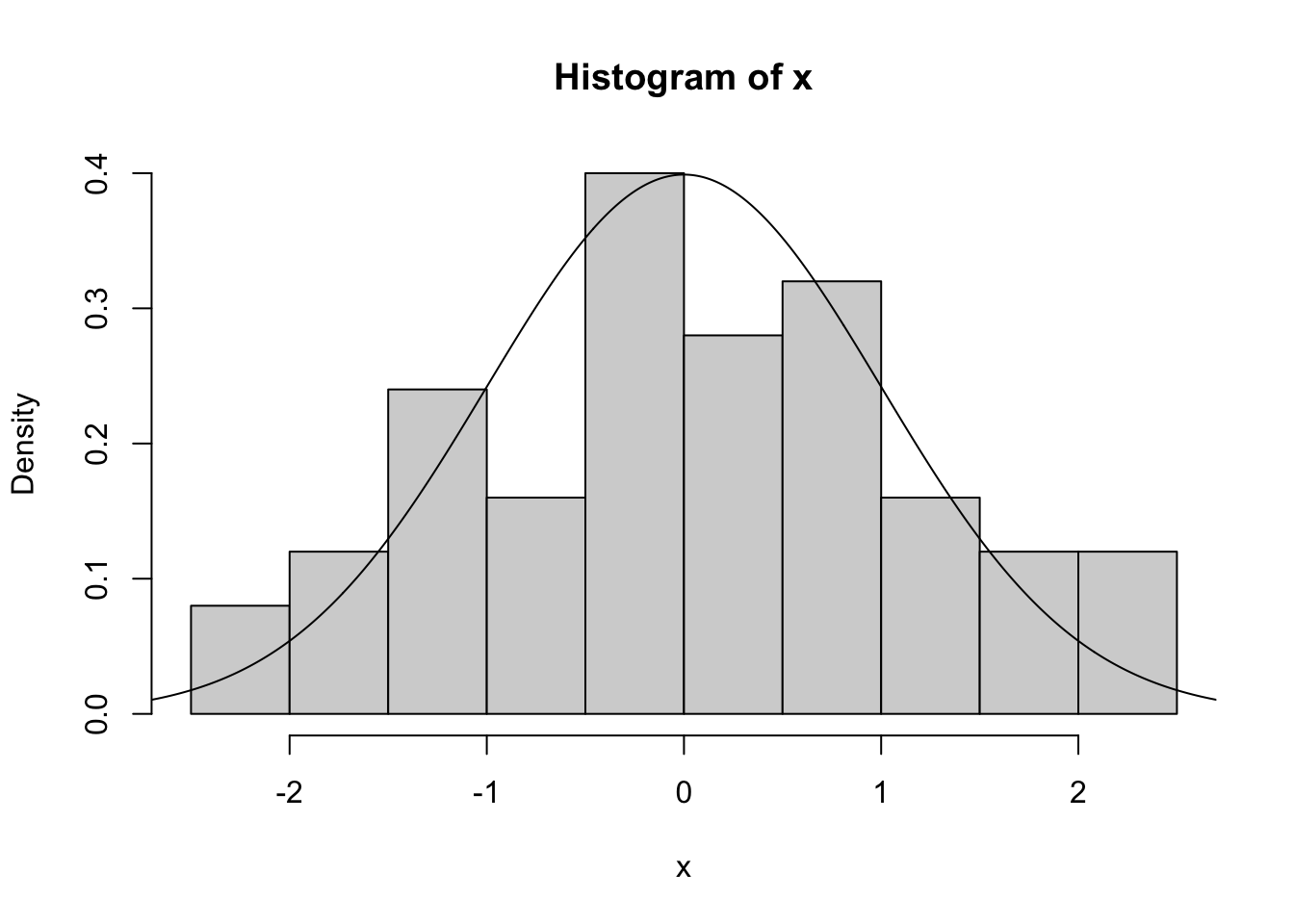
Vygenerujeme si pseudonáhodné čísla a zobrazíme spolu s histogramom.
library(ISwR)#set random seedset.seed(3214)#generate sample of size 50 from N(0,1)x <-rnorm(50)#look at the histogramhist(x,freq=F)lines(seq(-3,3,0.01),dnorm(seq(-3,3,0.01)))
Vieme, že naša náhodná premenná má strednú hodnotu \(0.\) Ak by sme to nevedeli, mohli by sme ju odhadnúť pomocou aritmetického priemeru z našej iid vzorky na základe ZVČ
\[\bar{X} = \frac{\sum_{i=1}^n X_i}{n}.\]
#sample meanmean(x)
[1] 0.05538502
sum(x)/length(x)
[1] 0.05538502
Podobne o variancii vieme, že je rovná 1. Mohli by sme ju odhadnúť na základe výberovej variancie
\[S^2 = \frac{\sum_{i=1}^n (X_i-\bar{X})^2}{n-1}.\] Všimnime si, že v menovateli je \(n-1\) a nie \(n.\) Pre veľké \(n\) je rozdiel zanedbateľný ale takto skonštruované \(S^2\) má tú výhodu, že je nevychýlené, teda \(\text{E}[S^2] = \text{Var}[X].\)
#sample variancevar(x)
[1] 1.36166
sum((x-mean(x))^2)/(length(x)-1)
[1] 1.36166
#sample standard deviationsd(x)
[1] 1.166902
sqrt(sum((x-mean(x))^2)/(length(x)-1))
[1] 1.166902
Pri výberovom mediáne (alebo výberovom p-percentnom kvantile) sa jednoducho pozrieme, že kde musíme rozseknúť usporiadané dáta tak, aby na jednej strane bola polovica a na druhej druhá polovica (alebo p% dát a (1-p)% dát). V prípade párneho počtu dátovej vzorky zoberieme priemer dvoch hodnôt.
Cvičenie 5.1 Spočítajte varianciu náhodnej premennej \(X \sim Bin(10,0.25)\) (súčet úspechov 10 nezávislých hodov neférovou mincou s pravdepodobnosťou hlavy 25%) a porovnajte so simuláciou.
Cvičenie 5.2 Spočítajte pravdepodobnosť toho, že počet zemetrasení \(X \sim Pois(2)\) bude aspoň 3 a porovnajte so simuláciou.
Cvičenie 5.3 Spočítajte 95%ný kvantil \(X \sim N(3,4)\) náhodnej premennej a porovnajte so simuláciou.
Cvičenie 5.4 Majme dve skupiny ľudí, ktorých IQ je charakterizované týmito rozdeleniami: \(X_1 \sim N(110,20^2)\) a \(X_2 \sim N(120,5^2).\) Prvá skupina má nižší priemer ale zasa vyššiu varianciu. Majme 10 ľudí z prvej skupiny a 5 ľudí z druhej skupiny. Odhadnite pravdepodobnosť, že človek s najvyšším IQ bude z druhej skupiny. Aká veľká by musela byť druhá skupina, aby bola táto pravdepodbnosť čo najbližšia 50%?
Cvičenie 5.5 Uvažujeme dva rôzne webshopy a ten istý produkt. Po istom čase pozbierali webshopy skúsenosti zákazníkov. V prvom bolo 24 z 25 ľudí spokojných, v druhom bolo 353 z 400 spokojných. Ľudia hodnotili produkt, nie webshop a produkt bol ten istý. Vieme, že šanca, že uvidíme aspoň 24 ľudí spokojných v prvom obchode je rovnaká ako to, že uvidíme aspoň 353 v druhom obchode. Aká je skutočná spokojnosť zákazníkov s týmto produktom?